
高性能缓存架构
2021/06/04 11:47 分类: 技术交流 浏览:0
互联网应用飞速发展,数据量越来越大,对数据存储访问的性能要求越来越高,单纯依靠存储来提高性能显然已经不够
特别是对于需要运算出来的数据,存储服务压力更大,早期第一时间出现的性能瓶颈也是因为数据存储,例如通过Mysql需要实时获取,股票价格,存储查询都显得特别无力,单纯的Mysql性能无法支持
目前应用,用户浏览比较多,查询压力比较大,而写的压力不大,例如一条信息发布,但是可能会有千万人来阅读,同时查询的人特别多。Mysql无法应对。所以我们通过redis缓存,单台redis qps超过10w,可以应对存储系统的不足,并且redis不支持ACID效率更高
|
第一次就访问数据库服务器 以后就访问缓存服务器 |
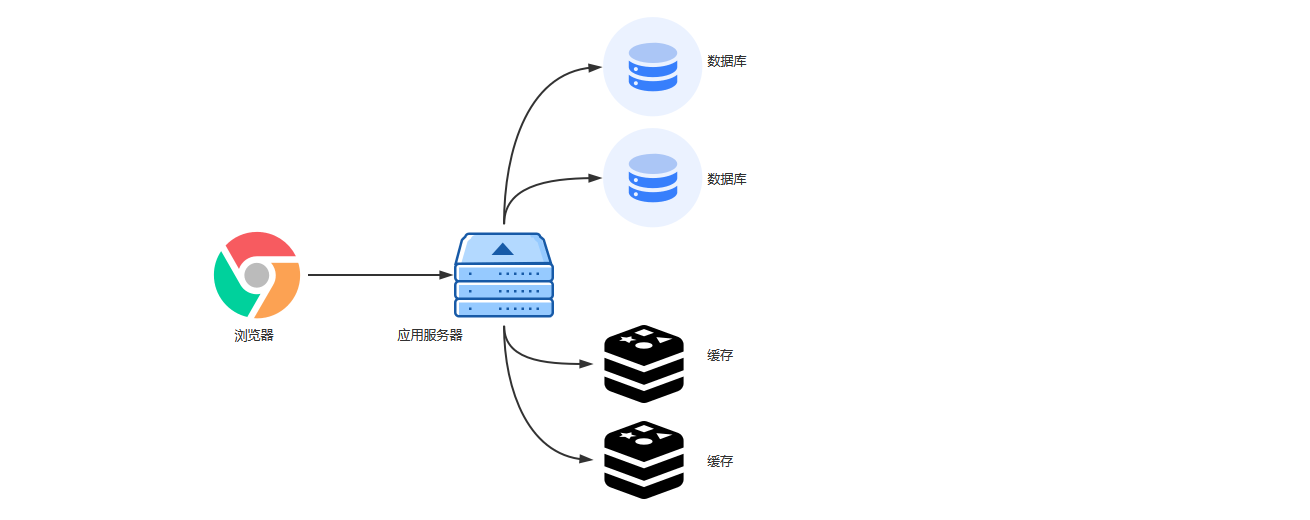
缓存虽然能够大大减轻存储系统的压力,但同时也给架构引入了更多复杂性。架构设计时如果没有针对缓存的复杂性进行处理,某些场景下甚至会导致整个系统崩溃。今天,我来逐一分析缓存的架构设计要点。
缓存穿透
缓存穿透,客户访问数据,由于缓存中没有数据,而直接到数据库服务器查询数据,缓存没有达到应有,解决数据库服务器压力的目的,极为缓存穿透
|
|
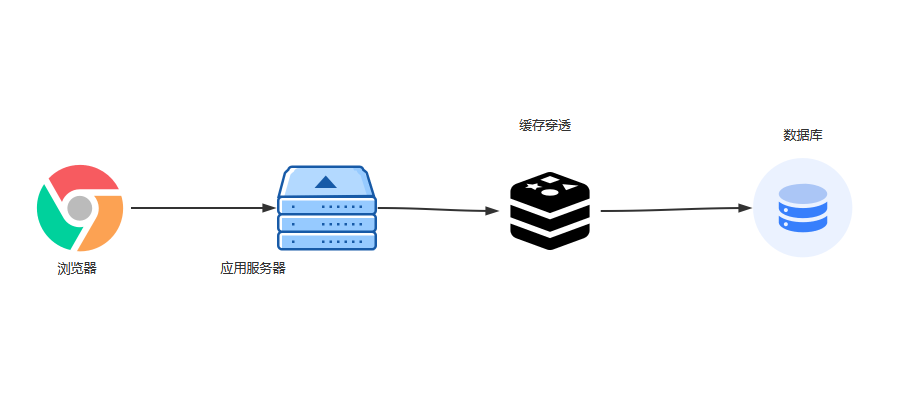
缓存穿透的原因一般有两点
1. 缓存中的数据不存在
(1) 例如:我们要查找的数据确实在数据库中首先不存在,所以更加不可能去缓存中缓存数据,这就导致了,查不到的数据,不会走缓存,而会不断的到数据库中查询,缓存也没有达到减轻数据库服务器压力的目的,从而导致系统奔溃
(2) 解决办法:如果到数据库服务器查询了该数据,确实没有该数据,那么就对该数据在缓存中,缓存一条空信息,以后再查这条数据就不走数据库了。
2. 缓存生成消耗大量系统资源
(1) 例如一般系统:在刚开始上线时,都会初始化系统,把系统应该缓存的数据缓存到,缓存服务器,但是新数据诞生,老数据淘汰,避免不了,缓存中,存在我们查询不到的数据,
(2) 一般系统,我们只缓存部分数据,例如商品也数据,一般大家也都只查询前几页的数据,但是避免不了,别人到通过爬虫取数据,导致访问所有数据,进而缓存大量数据。导致缓存消耗大量资源,这种情况,我们只能在系统中判处处理
缓存雪崩
|
|

在高并发业务中,当缓存过期,被清理之后,业务系统需要重新生成缓存数据,而有些缓存数据的生成需要消耗大量系统资源。对于一个高并发的项目来说,无疑时灾难性的,会导致系统性能急剧下降。拖慢系统,甚至宕机
高并发业务中:
1. 当业务访问,发现缓存不存在,用户访问的同时出发业务系统,启动线程生成缓存,在高并发项目中,几百毫秒内,会有成百上千个请求,意味着有可能同时开启上千个线程缓存数据,因为其他线程也不知道有线程正在缓存数据,系统性能会快速的被拉低,甚至宕机。
解决办法:
2. 更新锁:
(1) 如果有线程再缓存数据数据了,那么加锁,其他用户访问,在没有缓存完成数据前,返回提示信息
(2) 分布式通过ZooKeeper 加分布式锁
3. 后台更新
(1) 数据可以设置永久有效,缓存如果过大可以踢掉一些数据,如果业务线程发现缓存中没有数据,那么可以向后台线程消息队列中,发送一个消息,通知更新缓存
(2) 后台更新,还可以不用等到用户触发,可以设置定时任务,定时更新
缓存热点
对于热点数据,我们可以重点缓存,例如关注度比价高的金融热点,消息一发布,所有金融界认识都第一时间月阅读,但是如果每次都命中同一份缓存数据,缓存服务器的压力也是比较大的,拷贝100份缓存在不同的缓存服务器,分撒到不同服务器,并且对对每一个份数据标号,每次读取缓存数据,都随随机读取缓存数据,且每一份数据设置过期时间都不一样,避免所有缓存数据同时失效,引发雪崩效应
设计实现
缓存和存储都是相关的,设计方案实现,我们可以集中放在存储访问模块中,可以通过代码实现,也可以通过中间层,或者中间件实现
赞 0


