
单字节与多字节字符的处理方式
2017/03/20 14:54 分类: 技术交流 浏览:258
我们在写PHP代码时,时常会遇到一些问题,比如使用strlen时,会显示出一些无法理解的结果:
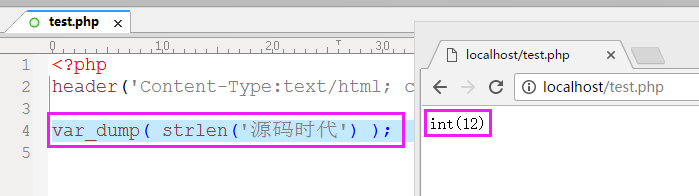
(明明只有四个中文字,结果却显示出是12个字)
又或者截取字符串时,可能会遇到只截取到一半的情况,有点像乱码的节奏:
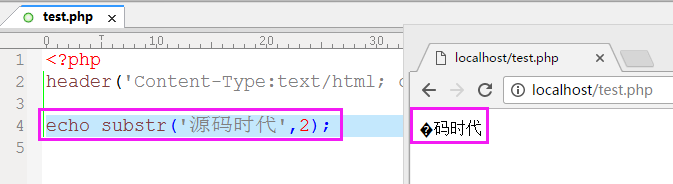
(substr从第2个位置开始截取不是应该出现“时代”两个字吗)
这些问题是怎么产生的呢?接下来我来和大家一起研究一下。
首先,我们来看一下在PHP中字符的概念,在PHP编程语言中,字符是分为单字节字符和多字节字符,单字节字符在存储时占1个字节,比如:英文字母、数字、常用的特殊字符等等。 多字节字符指的是在储存时占多个字节的字符,比如:中文汉字。
那么,为什么会产生单字节字符和多字节字符呢?这里我们就得来了解一下字符的存储原理和字符集的概念了。
在计算机中我们看到的字符只是一个逻辑符号,真实的存储是转换成二进制编码进行存放的。而文字实际上就是矢量图形,只不过在字符集编码时给了这些图形相应的编号,于是在存储时,将编码转换成二进制进行保存而已。
那单字节字符是怎么回事呢,这个我们就得来看一下ASCII码了。

(ASCII码表截图和说明)
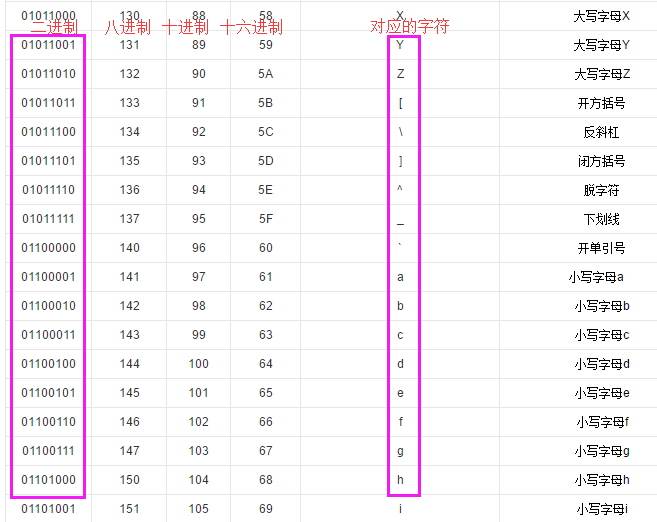
从上表中我们可以看出,所有英文字母的排列都在十进制127以前,转换成二进制进行存储时,用1个字节的前7个二进制位就可以解决了。 所以英文、数字、常用特殊字符只占1个字节。
同理,由于中文字非常多,常用的都3000多个字,而且加上不常用的和繁体字,总共约为两万字,所以在排列时,肯定不可能在255(8个二进制位排满)以内全部排完。而且即使在互联网上使用中文时也同样会用到非常常用的英文和数字。 于是,就将中文的字全部排在了后面,不同的编码集位置不同。 中文常用的编码是 GBK、GB2312、BIG5、UTF-8 。
在GBK和GB2312中一个中文字占两个字节(序号转换成二进制在16个二进制位以内),在UTF-8字符集中一个中文字占三个字节(序号转换成二进制在24个进进制位以内)。在中文逐渐国际化的今天,我们最常用的是UTF-8编码集。
所以,本文开头所提到的两个问题也就自然而然了,由于一个中文字占3个字节,所以在显示字数时4个中文字显示成12个字。 而在从第二位开始截取时,由于一个中文字占3个字节,所以就将“源”字切成了两半,导致看上去像乱码。
关键是,这些问题如何解决呢?
要解决这些问题其实很简单,PHP是支持多字节字符的,只不过需要打开一个叫“mbstring”的扩展:
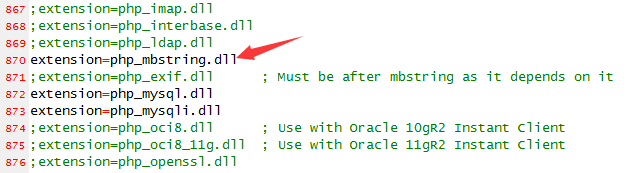
(在php.ini配置文件中去除前面的注释符号,让mbstring扩展生效)

(phpinfo看到的支持已开始)
然后再在字符串函数的前面加 mb_前缀, 比如:mb_strlen(),这是为了好理解,实际上这是 mbstring扩展的独特函数,只是取的名字与单字节字符保持一致。 由于编码种类非常多,所以多字节处理函数在参数的最后一位必须指定当前的编码集。 语法比如: mb_strlen('字符串','所用编码集');

(使用了多字节函数,就能正常显示字数了)
最后,给大家汇总一下常用的多字节函数吧:
mb_split 使用正则表达式分割字符串形成一个数组
mb_strlen 返回字符串中字符的个数
mb_strpos 在字符串中查看子字符串返回首次出现的问题
mb_strrchr 查找字符串在另外一个字符串中最后一次出现的位置并截取到最后
mb_substr 截取字符串
赞 0


