
如何基于node爬取网页源文件
2017/03/27 12:00 分类: 技术交流 浏览:61
大家好,我是源码时代H5前端学科何老师,今天给大家带来关于node爬虫的一个小案例。来我们直接进入主题:
1.打开Hbuilder,新建项目,然后新建crawler.js文件。
2.键入如下代码:
var http=require("http"); //引用http模块
var url='http://cd.58.com/'; //定义一个要爬的网页地址
/*
* 使用http对象的get方法获取url网页的内容,
* 第2个参数是回调响应response的结果怎么处理
*/
http.get(url,function(res){
//定义一个html字符串
var html='';
//当respone由data事件触发的时候,通过函数回调,把爬的数据组装到html字符串中。
res.on('data',function(data){
html+=data
})
//当response对象由end事件触发的时候,回调函数实现向控制台输出html字符串的内容。
res.on('end',function(){
console.log(html);
})
}).on('error',function(){ //当触发error事件的时候,控制台输出‘’
console.log("错误")
})
3.在当前文件的路径下打开命令窗口,输入node crawler.js

运行结果:
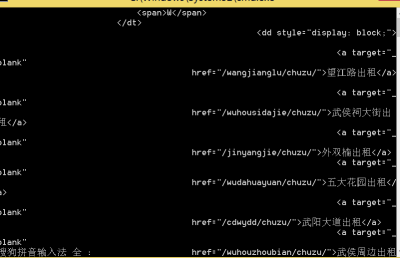
逐步推进:如何爬取网页源文件中的具体信息。
在服务器端解析html,可以在node环境中安装 cheerio模块,此模块类似于Jquery语法,可以方便快捷进行html内容解析。安装语法如下:
打开命令窗口
npm install cheerio;

在hbulider中新建:crawler58.js键入以下代码:
var http=require("http"); //引用http模块
var cheerio=require("cheerio");//引用cheerio
var url='http://cd.58.com/chuzu/?PGTID=0d100000-0006-6648-121f-922f100df9e5&ClickID=4'; //定义一个要爬的网页地址
//获取网页文字相关内容
function filterContent(html)
{
var $=cheerio.load(html);
// var meta=$("meta"); //获取meta标签的数据
// console.log(meta)
var rooms=$(".listBox .listUl li");
//获取房源列表
var roomsdata=[];
rooms.each(function(item){
var room=$(this);
var room_imgsrc=room.find("img").attr("src");//图片路径
var roomtitle=room.find(".des h2 a").text().trim();//房屋标题
var Area=room.find(".des .room").text();//面积
var money=room.find(".money b").text();//租金
//将信息封装成一个房屋信息的对象
var romminfo={
img:room_imgsrc,
title:roomtitle,
rarea:Area,
money:money
}
//将房屋对象添加到roomsdata数组中
roomsdata.push(romminfo);
});
返回数组
return roomsdata;
}
//打印数组
function printInfo(rooms){
rooms.forEach(function(item){
var title=item.title;
console.log("标题:"+title+"\n面积:"+item.rarea+"\n价格:"+item.money+"\n图片:"+item.img+"\n");
})
}
/*
* 使用http对象的get方法获取url网页的内容,
* 第2个参数是回调响应response的结果怎么处理
*
*/
http.get(url,function(res){
//定义一个html字符串
var html='';
//当respone由data事件触发的时候,通过函数回调,把爬的数据组装到html字符串中。
res.on('data',function(data){
html+=data
})
//当response对象由end事件触发的时候,回调函数实现向控制台输出html字符串的内容。
res.on('end',function(){
//console.log(html);
var rooms=filterContent(html);
printInfo(rooms);
})
}).on('error',function(){ //当触发error事件的时候,控制台输出‘’
console.log("错误")
})
在命令窗口中执行命令运行此crawler58.js

运行结果,成功抓取相关信息:

赞 0


